在现代信息世界中,我们有许多照片、文件、视频等需要存储。我相信几乎所有人都尝试过使用 Google Drive 或 Dropbox。
功能需求
- 用户可以从任何设备上传和下载文件。
- 用户可以通过替换相同的文件名来更新文件。
- 用户可以通过电子邮件链接将文件和文件夹分享给其他人。
- 用户可以随时从任何设备删除文件和文件夹。
- 删除的文件和文件夹将在回收站中存储 15 天。
- 系统应该支持离线编辑。用户可以在离线状态下添加/修改文件和文件夹名称,一旦网络恢复,更改将与远程服务器同步。
- 用户可以进行文件版本管理,以恢复文件的先前版本。(系统可以支持多次更改的同一文件的多个版本,带宽和所需空间将显著增加)
- 系统可以支持跨设备的文件和文件夹同步。
- 系统允许每个用户免费上传高达 10 GB 的文件。
- 系统将为不同存储大小提供不同的市场计划。
非功能需求
- 系统必须高度可靠。任何上传的文件都不得丢失。用户可以恢复其重要文件。
- 系统可以支持每周 7 天 24 小时。
- 用户可以随时升级其计划,并立即使用系统。
- 用户必须能够轻松地将其系统与其他应用程序集成。例如,系统支持通过其他应用程序共享文档。
- 系统可以提供延迟或并发利用(这意味着以高效的方法从云中反复上传和下载完整文件)。
存储估算
- 用户数量 = 5 亿
- 活跃用户数量 = 1 亿
- 用户平均存储的文件数量 = 300
- 每个文件的平均大小 = 200 KB
- 总文件数量 = 5 亿 * 300 = 1500 亿
- 需要的总存储空间 = 1500 亿 * 200 KB = 30 PB
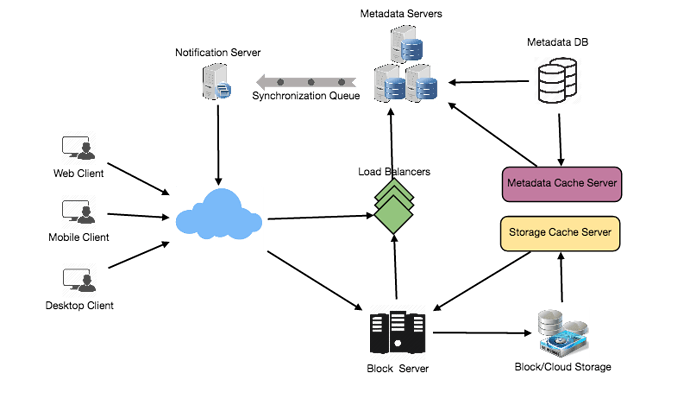
系统组件
- 客户端(安装在您的桌面或移动应用程序中,用于访问与存储相关的应用程序)
- 监视用户机器上的工作区文件夹,并通过与远程服务器同步文件来维护一致性。因此,它必须由 4 个基本组件组成,即监视器、分块器、索引器和内部数据库。
- 监视器将监视本地工作区文件夹,并通知索引器用户执行的任何操作(添加、删除、替换和更新文件或文件夹),并追踪来自其他设备的任何更改,这些更改由同步服务广播。
- 分块器将文件分成更小的块,并从这些块中重建文件,以便完整的文件可以在没有任何丢失块的情况下传输。分块算法将检测用户修改的文件部分,并仅将已修改的部分传输到云存储,从而节省带宽和同步时间。
- 索引器将处理来自监视器的事件,并更新内部元数据数据库。一旦成功从云存储下载或上传了块,索引器将与远程同步服务通信,广播更改给其他客户端,并更新远程元数据数据库。
- 内部元数据数据库将跟踪所有文件、块、任何已更新的版本以及其在文件系统中的位置。
- 客户端应用程序将通过请求上传、下载和编辑 API 与后端云存储服务器进行通信。客户端还与远程同步服务进行交互,以处理任何文件元数据更新,例如文件名、大小、修改日期等。
- 元数据数据库
- 保持有关文件、块、用户、设备、工作区和存储位置的版本和元数据信息。
- 元数据数据库可以是关系数据库,如 MySQL,也可以是 NoSQL 数据库服务,如 DynamoDB。
- 同步服务在多个用户同时处理同一文件时,提供文件的一致视图。
- 由于 NoSQL 数据存储不支持 ACID 属性,编程代码会将 ACID 属性与 NoSQL 数据库结合在一起,用于同步服务的逻辑。
- 同步服务
- 更新客户端创建的文件或文件夹。
- 将客户端的本地数据库与存储在远程元数据数据库中的信息同步。
- 使用 HTTP 长轮询从云存储获取响应,或在脱机一段时间后将文件和更新发送到云存储,一旦重新脱机,将向所有设备或用户发送通知。
- 同步服务还尝试在客户端和云存储之间传输更少的数据,以实现更快的响应时间,因此使用差异化算法来减少需要同步的数据量。不再将整个文件从客户端传输到服务器,而是传输两个版本文件之间的差异。仅传输已更改的部分(块)。这减少了终端用户的带宽消耗和
云数据存储。服务器和客户端将计算哈希值,以查看是否更新修改的块。该过程称为数据去重。
- 消息队列服务
- 这是一个处理读写请求数量的消息中间件。
- 一个可扩展的消息队列服务,支持客户端和同步服务之间的异步通信。
- 可用性和可靠性必须被设计得最适合消息队列服务。
- 请求队列:此队列将在所有客户端之间共享。当客户端执行任何更新和请求时,此请求将发送到消息队列服务,然后由同步服务进一步处理,最后更新元数据数据库。
- 响应队列:每个客户端都有一个相关的响应队列,因为每个客户端都有一个单独的响应队列。
- 一旦文件更新,同步服务将通知所有响应队列有关更改的信息,然后响应队列将通知每个客户端进行的更改。
- 云/块存储
- 存储文件的块
- 使用 Amazon S3 服务
- 客户端将使用 API 服务与云存储进行交互
文件处理工作流程:客户端 A 将块上传到云存储,然后更新元数据并提交更改,然后获得确认。服务器将通知客户端 B 和 C 有关更改的信息。客户端 B 和 C 接收元数据更改并下载更新的块。
数据去重:消除数据的重复副本。这还可以减少相同数据传输(发送的字节数)以提高传输速率。对于每个传入的块,都会打上一个哈希标签,然后计算并将该哈希与现有块的所有其他哈希进行比较。
a) 后处理去重:新块存储在存储设备上,并且将分析块以了解它们是否是重复的。优点是,客户端不需要等待哈希计算或查找完成,然后再存储数据,这会提高存储性能。缺点是短时间内会存储不必要的重复数据,并且会传输和消耗带宽。
b) 内联去重:去重哈希计算可以实时执行,以便系统可以识别重复块,然后仅存储不存在的块。优点是优化网络和存储使用。缺点是消耗用户的时间并降低存储性能。
- 缓存
- 在 Google Drive / Dropbox 系统设计中有两种类型的缓存
- 用于块存储的缓存
- 使用像 Memcache 这样的现成解决方案的缓存,可以存储带有其相应 ID/哈希的整个块和块服务器
- 可以采用最近最少使用(LRU)缓存策略。
- 负载均衡器(LB)
- 在客户端和块服务器之间
- 在客户端和元数据服务器之间
- 在后端服务器之间平均分配传入的请求
- 安全性/权限和文件共享
- 上传/下载的文件将与远程服务器同步
- 不允许对单个文件进行多个操作(并发问题)
- 如果在某个过程中出现了某些连接问题,客户端必须重新上传或下载整个文件,或者恢复下载或上传块。
系统 API
- Upload(string uploadToken, fileInfo file, userInfo user)
- Edit(string authToken, fileInfo file, userInfo user)
- Delete(string authToken, fileInfo file, userInfo user)
- Download(string authToken, fileInfo file, userInfo user)
- GenerateToken (string userName, string password)
高级系统架构
详细系统架构

