为什么查询一行数据也很慢?
1.MySQL数据库本身被堵住了,比如:系统或网络资源不够
2.SQL语句被堵住了,比如:表锁,行锁等,导致存储引擎不执行对应的SQL语句
3.确实是索引使用不当,没有走索引
4.表中数据的特点导致的,走了索引,但回表次数庞大
SQL语句被堵住的原因
- 表锁
1 | mysql> select * from t where id=1; |
长时间不返回,一般碰到这种情况的话,大概率是表 t 被锁住了。接下来分析原因的时候,一般都是首先执行一下
show processlist 命令,看看当前语句处于什么状态。然后我们再针对每种状态,去分析它们产生的原因、如何复
现,以及如何处理。

(performance_schema=on,相比于设置为 off 会有 10% 左右的性能损失)通过查sys.schema_table_lock_waits
这张表,我们就可以直接找出造成阻塞的 process id,把这个连接用 kill 命令断开即可。

Waiting for table flush
另外一种查询堵住的情况是: 表t 等待被flush,正常flush是很快的
1 |
|
Waiting for table flush 状态的可能情况是:有一个 flush tables 命令被别的语句堵住了,然后它又堵住了我们的
select 语句。
等行锁
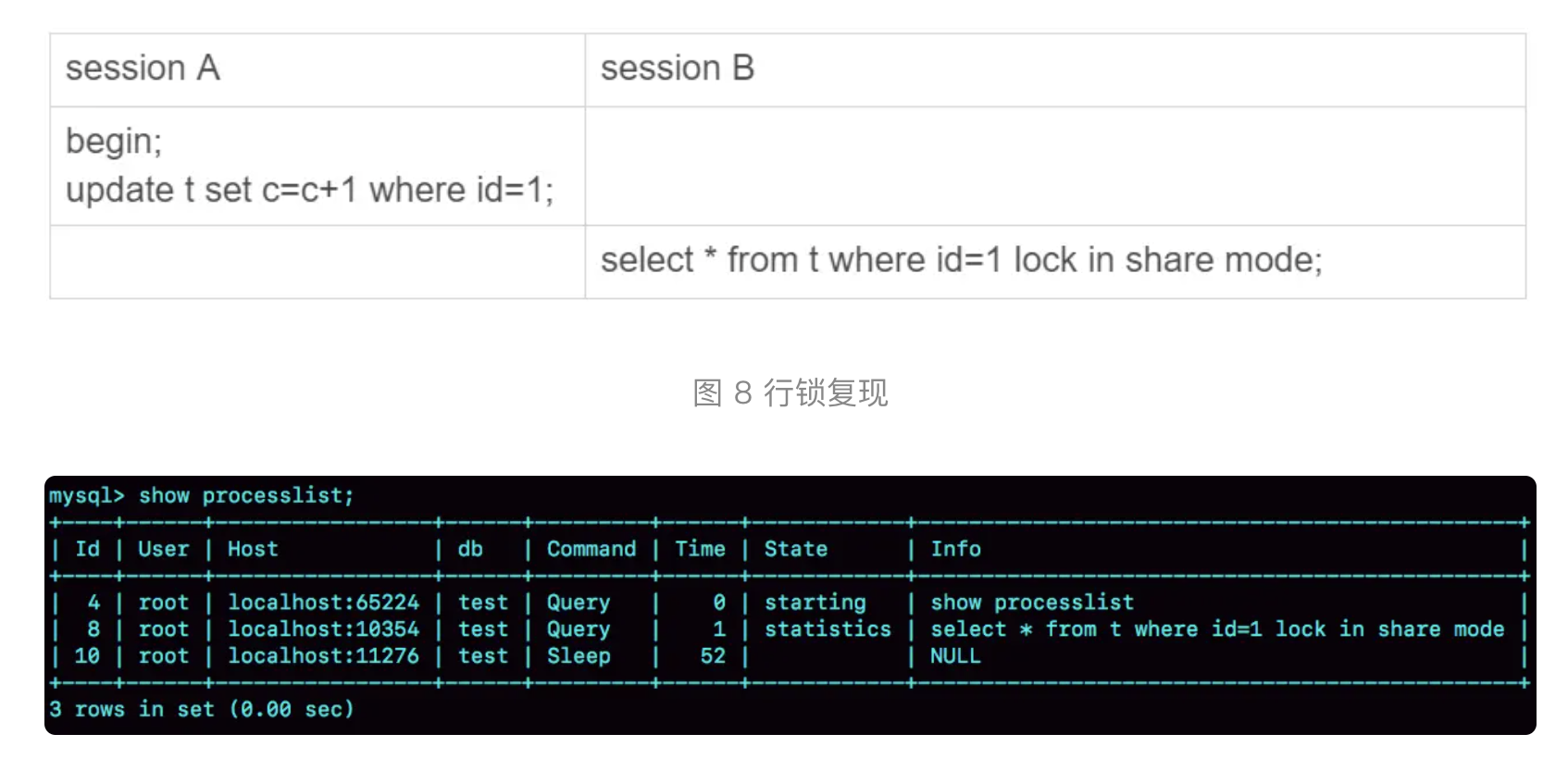
session A 启动了事务,占有写锁,还不提交,是导致 session B 被堵住的原因
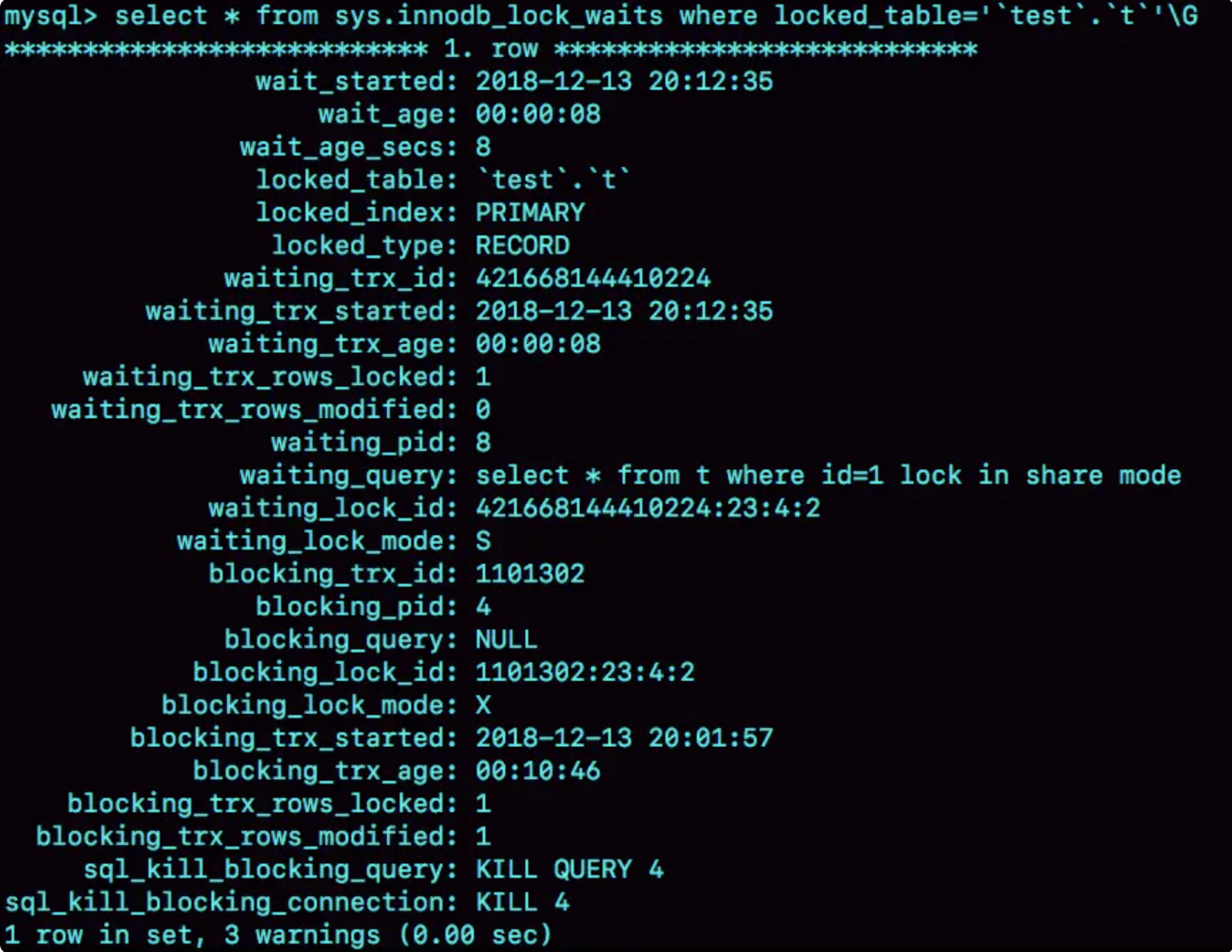
查出是谁占着这个写锁?
1 |
|
undo log
mysql在事物开始操作数据之前,会先将原始数据备份到一个undo log的地方,这样做的目的有两个。第一是为了
保证事物的原子性,如果事物在执行的过程中出现了某些错误,或者是用户执行了rollback的操作,mysql可以利
用undo log中的备份将数据恢复到事物开始之前的状态。第二是为了实现多版本的并发控制,事物在提交之前,
undo log中保存了未提交之前的数据版本,undo log可以作为旧版数据的快照供其他并发访问的事物实现快照
读。
快照读:SQL读取的数据是快照版本,也就是历史版本,普通的select查询的就是快照。innodb存储引擎的快照
读,读取的数据将由cache(原始数据)+undo(事物修改过的数据)两部分组成。
当前读:SQL读取的数据是最新版本,可以通过锁的机制来保证读取的数据无法被其它的事物修改。update,
delete,insert,select … lock in share mode,select … for update都是当前读。
除了undo log,Mysql数据库还有一个redo log的概念,mysql在事物开始之后,事物中操作的任何数据,会将最
新的数据备份到一个地方(redo log),就是在事物执行的过程中,开始将数据写入redo buffer中,最后写入redo
log中,具体的落盘策略可以自行配置。这样做的目的是:为了实现事物的持久性,防止在发生故障的时间点,尚有
脏页未写入磁盘,在mysql重启的时候,根据redo log重做,从而使事物未入磁盘的数据达到持久化这一特定。

session A 先用 start transaction with consistent snapshot 命令启动了一个事务,之后 session B 才开始执行
update 语句。
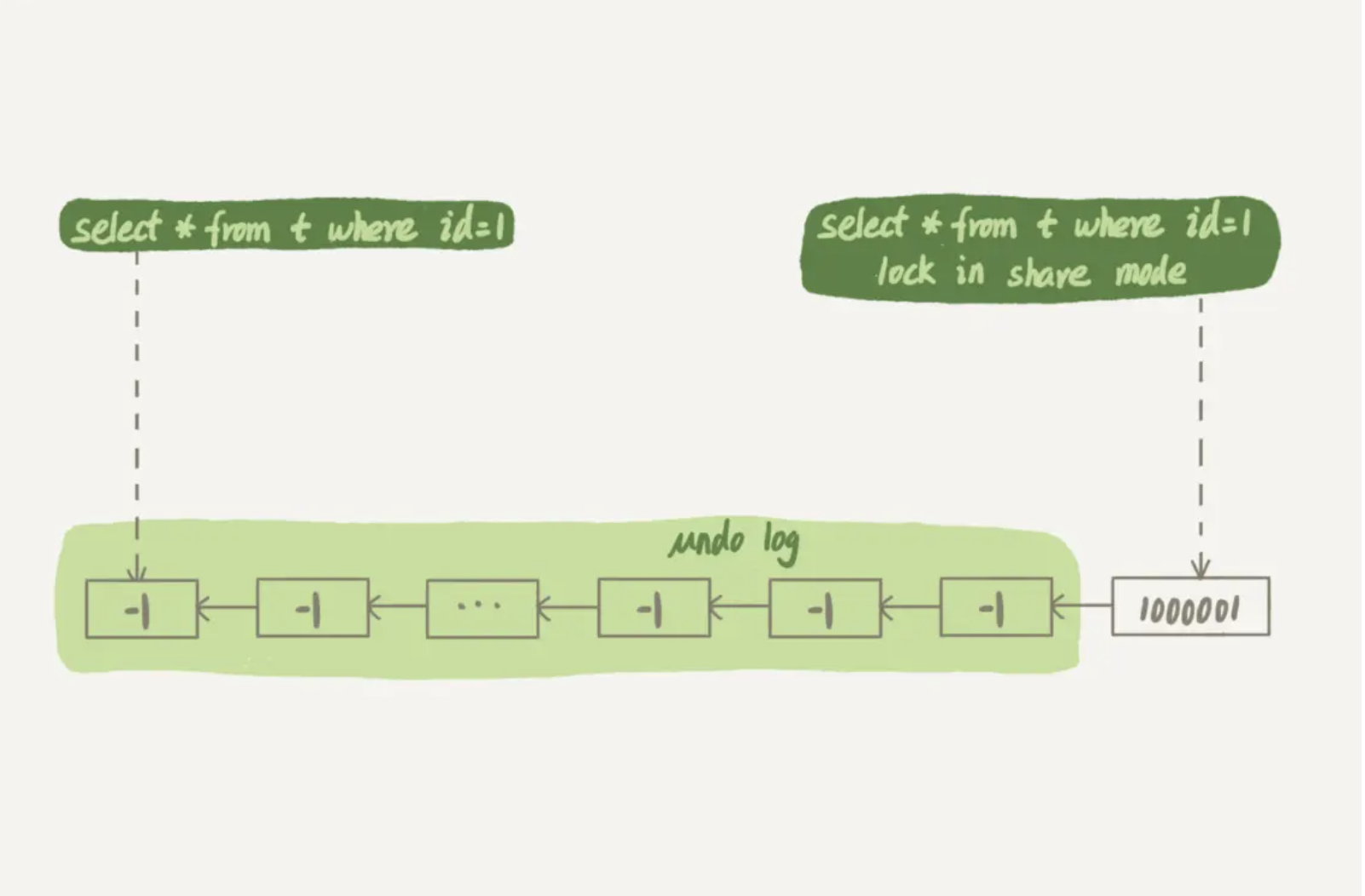
session B 更新完 100 万次,生成了 100 万个回滚日志 (undo log)。带 lock in share mode 的 SQL 语句,是当前
读,因此会直接读到 1000001 这个结果,所以速度很快;而 select * from t where id=1 这个语句,是一致性
读,因此需要从 1000001 开始,依次执行 undo log,执行了 100 万次以后 找到seesionA 一致性视图那个版本
才将 1 这个结果返回.

