查询优化
why?
优化的思路
客户端到服务器 其中包括 检验连接 查询缓存 解析 以及存储引擎涉及的调用 都会带来 cpu 内存 io等开销我们要
做的就是减少这些…
措施
一个是检查是不是返回了 程序不需要的大量数据,大量数据会带来大量cpu以及io等损耗…
一个是检查是不是扫了额外的行记录最简单的衡量查询开销的三个指标:1.响应时间2.扫描的行数3.返回的行
数, 关注数据的访问类型全表扫描 索引扫描 范围扫描 唯一索引扫描等…
using where?
 扫描大量数据, 返回却很少数的行?
扫描大量数据, 返回却很少数的行?

why 这样优化 ?
查询执行基础
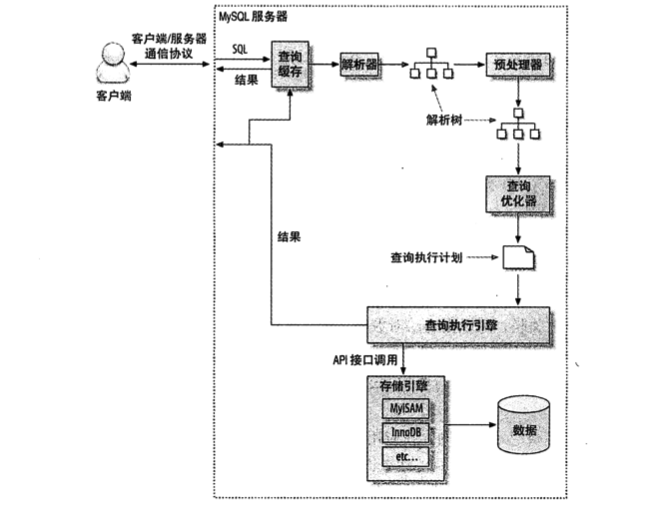
Mysql 客户端/服务器的通信协议
”半双工“协议,单方面一方进行推送,服务器推送数据给客户端,客户端推送查询给服务器,两个动作不能同时发生.
虽然这种通信比较简单快速,但是有一个缺点就是一方必须接收完全部信息才能响应. 这就是为什么客户端进行查询
数据包传送的时候需要进行大小限制“max_allowed_package” 以及这也是为什么在查询返回时加”limit“ 限制.
查询缓存
查询会和缓存中的查询进行匹配(一个区分大小写的Hash查找实现),如果完全匹配且权限没有问题则会直接返回数
据,反之如果有一个字节不匹配则不会命中缓存
查询优化以及处理(查询优化器)
这个阶段主要将 sql (转换成 ) —> 执行计划 -> mysql 依据这个执行计划去和存储引擎进行交互.
转换执行计划过程包括 解析sql, 预处理,优化sql 执行计划
查询优化包括静态优化以及动态优化,静态优化主要则是将where 层面的条件以代数的形式去比较选择,通常只做一
次,但是动态优化则是每次都会评估. 常见的mysql能够处理的优化类型:

查询执行引擎
Mysql 根据优化后的执行计划调用存储引擎的”handler API“,在解析运行时就为每张表生成handler
实列.
查询结果返回
服务器会将返回的结果集的每行数据以客户端/服务器通信协议进行封包处理,通过TCP协议进行传输,传输过程可能
会将封包数据进行缓存,进行批量传输.
其次如果查询是可以缓存,那么mysql 也会在这个阶段缓存对应的结果集

