为什么需要索引?
避免去扫全表,存储引擎先走索引找到对应值,然后根据索引记录找到对应的数据行.
优点的话,因为索引使用B+树结构 使得查询数据不再是随机IO,且避免去扫描全表
索引的策略(使用)
单列
不要在where 后面针对索引列计算,因为无法自动解析计算,所以需要避免索引列的一些计算

前缀索引
使列的前缀区分度趋近于这个列的完整列的区分度,这个时候可以考虑使用前缀索引,避免了索引过大,但同时区分度
差不多的情况.


索引合并的优化?
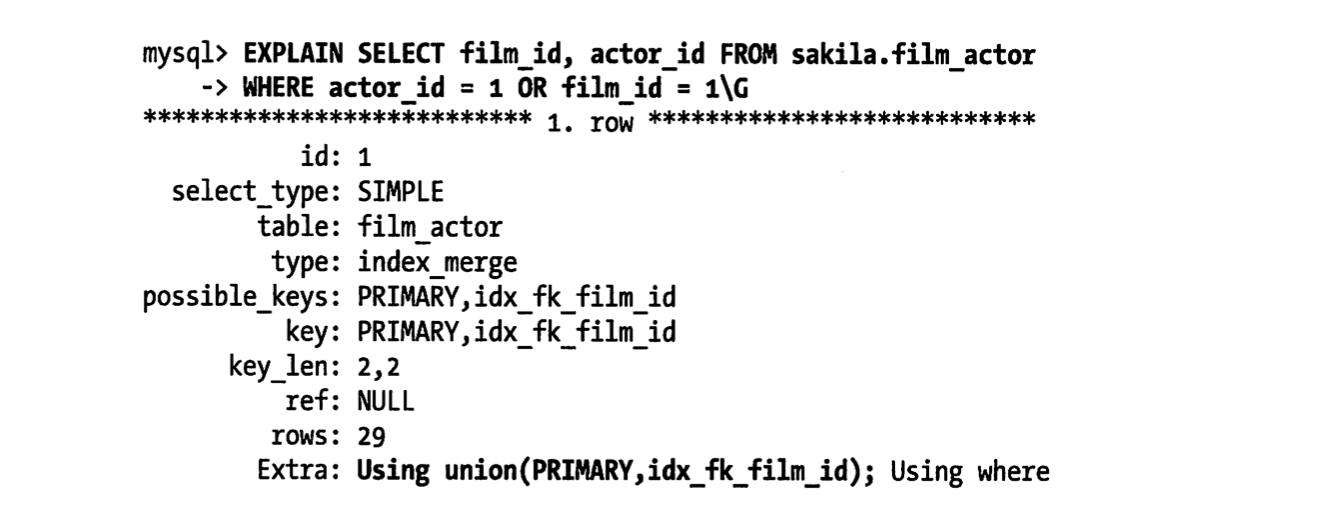
当服务器对多个索引进行联合操作时候,通常会消耗大量的CPU,内存等,有的时候or的索引列区分度不高,查询优
化器评估可能还不如扫全表来的成本低,可能就会放弃走索引. 所以遇到extra using union 合并索引优化的时候
需要看看自己的索引建立的是否合理?
如何选择合适的索引顺序?
如果没有排序或者分组的情况下,将区分度最高的列放在最前面是合理的,但如果涉及排序或者分组的时候,还是应该像前缀索引那样针对查询的结果集的区分度来做判断

聚簇索引
索引和数据行聚合在一起的,通常数据行不可能放在两个地方,所以聚簇索引的索引一般都是主键
聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一的非空索引代替
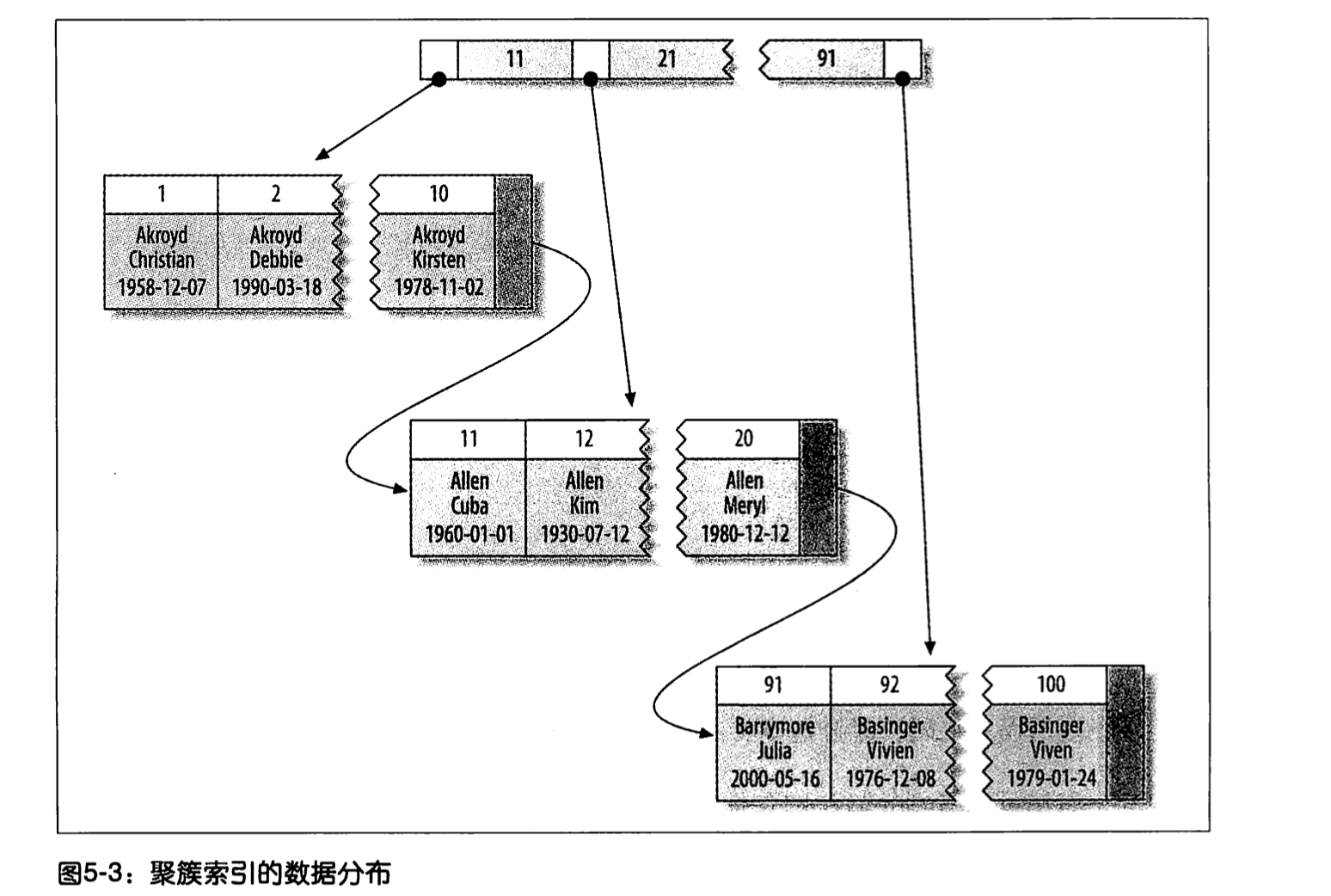
缺点: 当主键发生变化的时候,要插入一个已经满的数据行内时,会发生“页分裂”的问题, 导致数据行不连续,导致
全表扫描变慢,其次产生的”页分裂“ 也会占有额外的内存.
优点: 在B+树中查询会更快些,且使用覆盖索引扫描的查询可以直接用叶子结点上的主键
覆盖索引
索引包含了要查询的列,那么就没有必要回表查询(数据行).
优点: 如果走覆盖索引,返回的行数明显会少很多, 对服务器的缓存 IO 负载也会好很多
什么是“延迟关联“?
超多分页的问题
随着偏移量 offset 的增加,MySQL 需要花费大量的时间来扫描需要丢弃的数据。本质上就是 offset 过大导致
的大量回表 I/O 查询。
通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据。

使用索引来排序

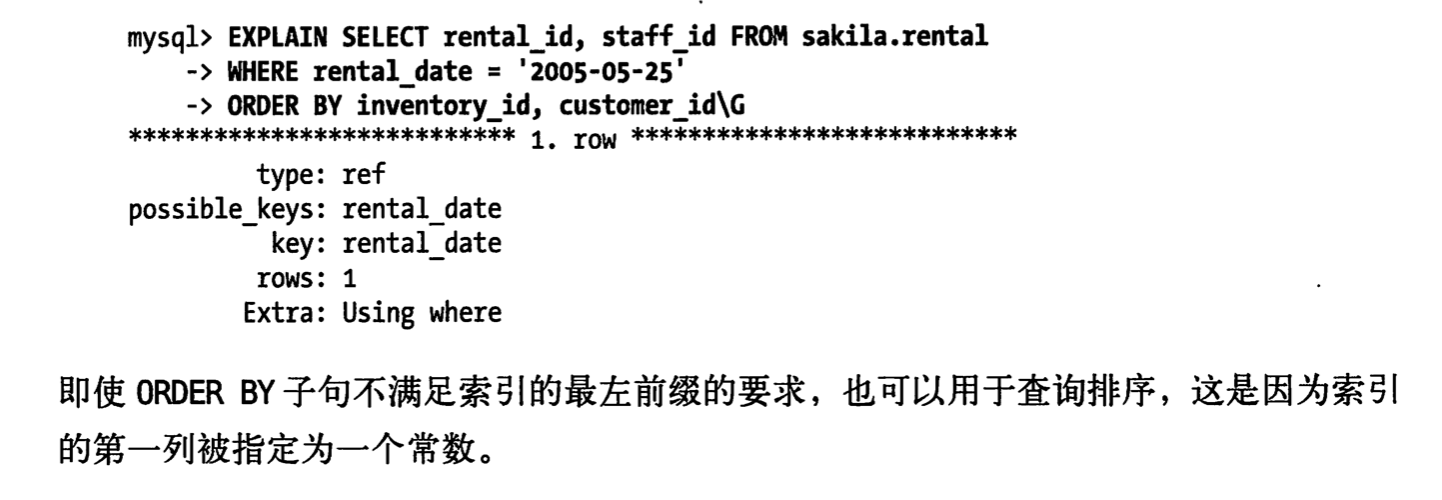
当第一列是范围查询的时候也不能使用索引作排序查询
1 | .... |
注意避免 冗余 & 重复& 未使用索引
索引和锁
在返回给服务器之前的,能够通过索引过滤无效行的形式去避免无效行的锁,返回到服务器数据可以通过where 过滤
之后释放锁.

use index 索引返回过滤 1-5 行的数据 , use where 索引返回行给服务器,应用 where 过滤

虽然查询只返回了24行的数据,但实际获取的是14行之间的排他锁,InnoDB 会锁住第一行,因为查询优化器 选择
的执行计划是索引范围扫描
索引案例学习
IN or > ?
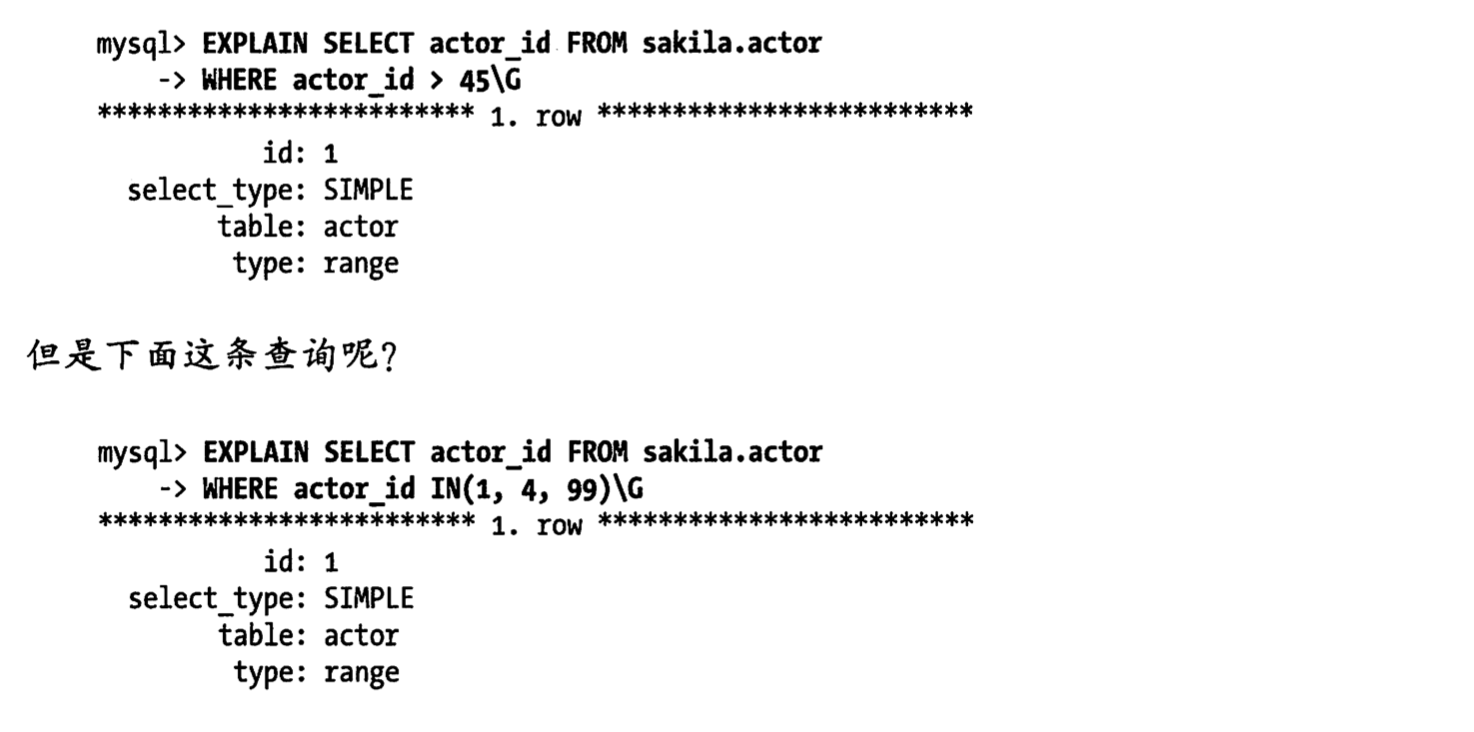
explain 结果来看无法区分 这二者的区别,但是 可以从值的范围和多个等于条件来得出不同,第二个就是等值查询
那二者在查询效率上有什么区别吗?
简单的来说第二种等值查询后续列可以继续使用索引,但是第一种范围查询后续列不可以使用索引,因为查询只能使
用索引的最左匹配.所以应该尽可能将范围查询放在索引列的后面.以便优化器可以使用尽可能多的索引列.
总结
服务器从存储中读取的块尽可能多的包含所需要的行
顺序IO 比随机IO快,特别是对机械硬盘,如果服务器能够顺序获取数据,那服务器则无需额外的排序
覆盖索引是很快的,如果索引列能返回所有的查询数据,则存储引擎无需回表查询数据行

